Twilio Interview Preparation
First I want to say thank you my boyfriend Haotian. He prepared and designed all the interview questions for me and gave me lots of advice on both behavior questions, technical questions and reference materials. I really appreciate his selfless help and love.
Second, I would like to tell myself that most interviews focus on fundamental questions but not challenging problems, so no excuse for not solving those fundamental questions.
Behavior questions
- 自我介绍 一定要流利,稍微讲一下技术栈,project一句话介绍。Need written template
- project < 1min30s (不要太长,给technical部分留时间)
- Company and autopilot都要了解,要了解他们家API是做什么的,有没有用到自己的project中
Technical questions
- 能打字就打出来,公式难解释,也是因为coderpad是review材料,写在上面的东西能被interviewer记住。
- TFIDF除了text classification还可以做text similarity。Vector容易sparse,所以自己implement的时候不要存vector,就存dictionary。比较两个documents的时候,找dictionary的交集,忽略其他的。(相当于follow-up)
Other packages: SparseMatrix
- 开始处理数据之前要想好用哪些数据结构,而不是iteration之后再加用于存储的变量。
Twilio
Companies need to communicate with their customers frequently. For example, notifying customers when their orders ship, or providing support over the phone, or confirming their reservations by text. Customers usually want companies to connect with them on communication channels they use daily, but it is difficult for companies to build such a communication platform. Twilio is the cloud communications platform that more than 50,000 companies use as their platform for customer engagement. Twilio built APIs that are simply to use and it can support communication channels like voice, text, chat and video.
Autopilot is a fully programmable conversational application platform that can be used to build conversational applications such as messaging bots and interactive voice response. Developers can build models and deploy across multiple channels including text message, google assistant and Alexa. Autopilot uses Twilio’s NLP and machine learning engine that allows a virtual assistant to understand in real-time meaning of incoming communication.
Questions
- Could you tell me the daily workflow of a machine learning engineer in Autopilot team?
- Since Autopilot supports different communication channels, like Google Assistant and Alexa, does Autopilot use speech recognition model from Google Assistant and Alexa, or it just use the input acoustic data and perform natural language understanding by itself?
- How to test the reliability of models in Autopilot platform?
- I saw you are one of the founding members on Autopilot team and witnessed the product starting from scratch, could you share with me that what is the most challenging part when building Autopilot?
-
What kind of team culture do you have?
metrics
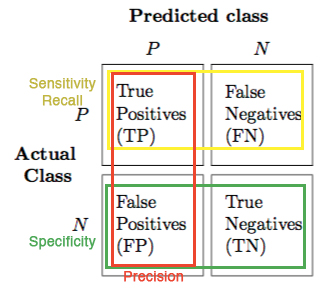
TP/TN/FP/FN
TP and TN are the observations that are correctly predicted. We want to minimize FN and FP.
True Positive (TP): correctly predicted positive values. (Actual class is Yes and the predicted class is also Yes) 正确被分到Yes类
True Negative (TN): Correctly predicted negative values. (Actual class is No and the predicted class is also No)
False Positive (FP): Actual class is False but predicted class is True.
False Negative (FN): Actual class is True but predicted class is False. 错误的判断为Negative类
accuracy
Accuracy is the ratio of correctly predicted observation to the total observations. However, it works when we have symmetric dataset where value of False Positive and False Negative are almost the same.
$Accuracy = \frac{TP+TN}{TP+TN+FP+FN}$
precision
Precision is the ratio of correctly predicted positive observations to all observations in predicted positive class (正确判断positive的数量+误判positive的数量). High precision relates to low False Positive Rate.
$Percision = \frac{TP}{TP+FP}$
recall
Precision is the ratio of correctly predicted positive observations to all observations in actual positive class (正确判断positive的数量+误判negative而实际上是positive的数量).
$Recall = \frac{TP}{TP+FN}$
F1 score
F1 score is the weighted average of precision and recall. F1 score is more useful when we have an uneven class distribution because it takes both false positive and false negative into account.
$F1\ Score = 2 * \frac{Recall * Precision}{Recall + Precision}$
Why 2 times …?
ROC AUC
 AUC means Area Under ROC Curve.
AUC means Area Under ROC Curve.
confusion matrix
TFIDF
TFIDF stands for term frequency inverse document frequency. This weight is a statistical measure use to evaluate how important a word is to a document in a corpus. TFIDF can be used in text mining field. The importance increases proportionally to the number of times a word appears in the document but it offset by the frequency of the word in the corpus. For example, words like “the” and “a” may appear frequently in a document, but they actually have little importance. When we do text mining, we hope to ignore those words and focus on really important words.
What is TF?
TF is term frequency, which measures how frequently a term occurs in a document.
$TF(t) = \frac{# \ of \ times \ term \ t \ appears \ in \ a \ document}{# \ of \ terms \ in \ the \ document}$
What is IDF?
IDF measures how important a term is by weighing down the frequent terms and scaling up rare words.
$IDF(t) = log \frac{total \ number \ of \ documents}{number \ of \ documents \ with \ term \ t \ in \ it}$
How to use TFIDF to do text classification?
What is L2 norm?
what is cosine similarity?
what is dot product in a geometry way?
Coding Problem
"""
problem:
suppose you have a bunch of docs
input file: format: <doc_id>, <word_list_separated_by_space> in each line
input.txt
1, cat dog cat pig
2, cat cat cat sheep
3, cat dog
4, sheep elephant
require to do:
cosine_sim(docid_1, docid_2)
cosine_sim_all(docid)
cosine_sim_new("cat dog elephant")
design a class and use any other helper functions you want.
"""
References
- https://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/
- https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc
- https://github.com/zhtpandog/tfidf
- http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/