Speech Recognition by Attention-based Deep Neural Network
Why Bi-LSTM?
LSTM can preserve information from inputs that has already passed through it using hidden state. Traditional LSTM only preserves information of the past because the only inputs it has seen are from the past. However, Bi-LSTM runs inputs in two directions, one from past ro future and one from future to past. Therefore, Bi-LSTM can run forward and backward, and preserve information both from past and feature using two hidden states combined.
For example, given a sentence “The boy went to … “, if a model want to predict the next word in this sentence, the traditional can only predict the next word based on the words before the word we want to predict. However, with Bi-LSTM, the model can see information further like “The boy went to … and did something”, it can help predict the word more accurately.
Why not GRU?
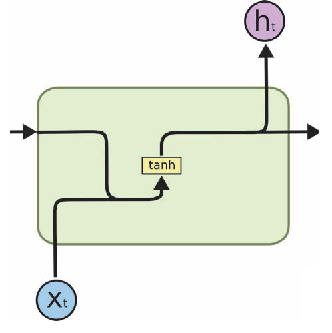 Simple RNN: simple multiplication of Input (xt) and Previous Output (ht-1), and passed through an activation function.
Simple RNN: simple multiplication of Input (xt) and Previous Output (ht-1), and passed through an activation function.
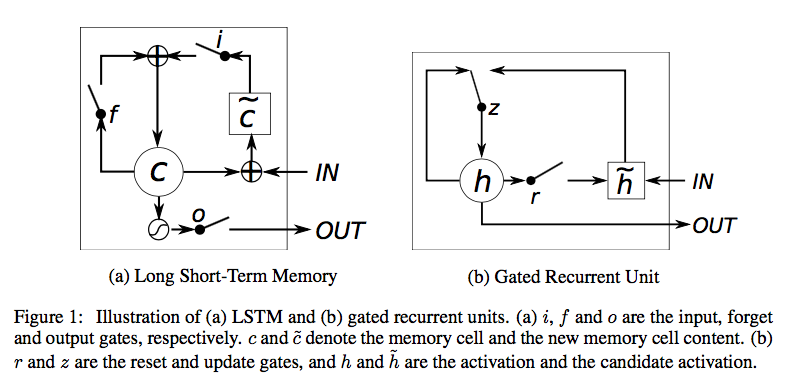
In LSTM, Forget and Output gates are introduced. Input gate regulates how much of the new cell state to keep. Forget gate regulates how much of the existing memory to forget. Output gate regulates how much of the cell state should be exposed to the next layers of the network.